Model Tests are Critical for Building Domain Knowledge

Testing is a critical but often ignored practice in machine learning. Building a machine learning system without testing is likely to produce bad outcomes at the worst time—when all the boxes feel checked, when the model is put into production, and when real people are impacted.
That is a typical (and true) story of testing in machine learning. But that story is all stick and no carrot. It skates clean over the most important product of testing for a data team to make progress: domain knowledge.
Machine learning projects grow in complexity as they move from the beginning stages towards maturity. Every iteration through development produces new insights, triggering activities like data cleaning, model tuning, or more labeling. These actions may be net value add, but regressions in small pockets of the system arise, sometimes invisibly. Testing defends against these regressions.
Testing often conjures a feeling of a chore, something that is good practice but not always necessary. Classic questions around testing arise, such as what is necessary to test and how sophisticated these tests should be. But viewing tests as building and systematizing domain knowledge shows the power of testing beyond a ratchet to prevent backsliding.
A combined view of testing with other knowledge-building activities, like error analysis and data annotation, encourages scientific progress as well as good engineering. Annotation, error analysis, and testing can be cross-leveraged, leading to compounding gains towards better system performance and deeper understanding of what is being modeled. Autonomous vehicles provide an interesting lens to understand this, and methodologies from Tesla’s self-driving unit demonstrate the power of this perspective.
Enabling knowledge-building through testing requires platform support. Platform teams must drive towards seamless experiences across testing and other activities. Tool-builders in the MLOps landscape should support them in that regard, prioritizing integration efforts over the Nth feature. It is not enough to solve a small vertical slice of the workflow if we care about long-term value for platform users.
Testing is Knowledge-Building
A model test is an assertion that a model should behave a certain way in some scenario. Technically, the scenario is specified by the model inputs, either one sample or many.
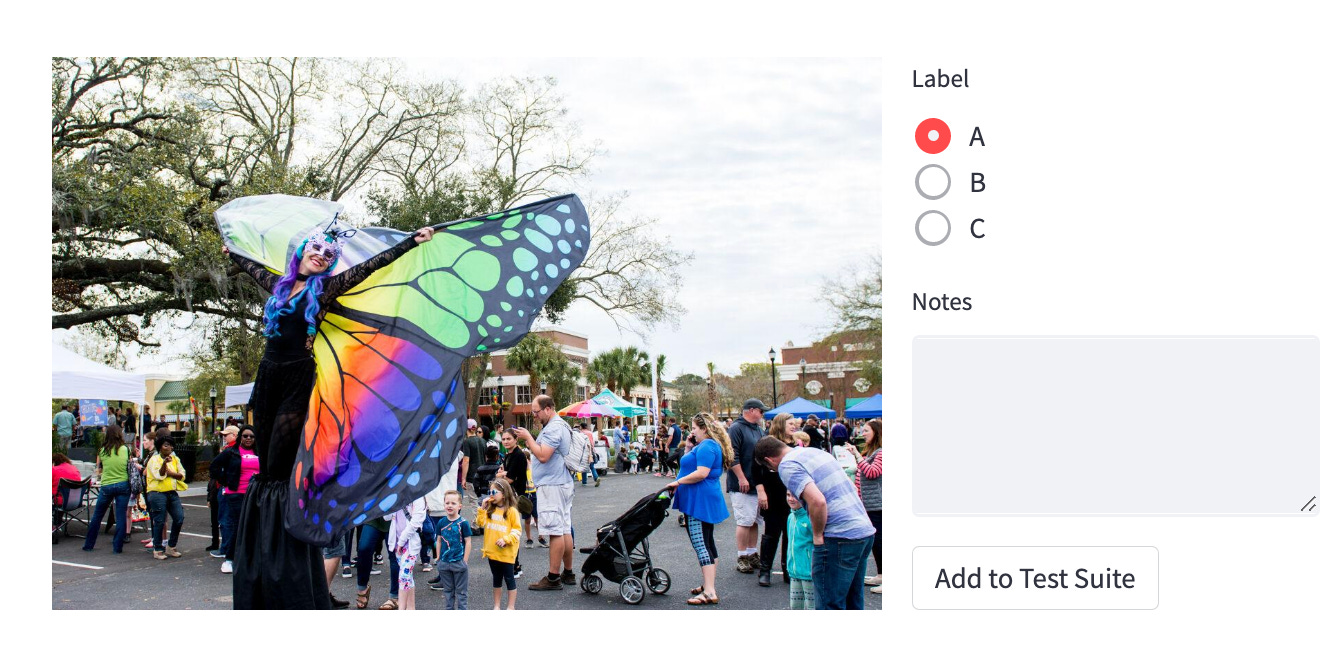
Before you have a test, you may not know a scenario even exists. Take an autonomous vehicle model that detects pedestrians in the field of view. It may not occur to you that pedestrians can have wings, abnormally long legs, or scintillating garments until a road test during a parade with many costumed pedestrians.

(Autonomous vehicles are a great example of how important testing is to AI safety.)
Finding out about these strange cases is learned through experience, or tacit knowledge. In order to leverage tacit knowledge it needs to be encoded into systems.
Implicit encoding of knowledge is the most prevalent because its convenient. A strange unexplained term in an equation or a “magical” configuration that happens to stabilize model training are examples of implicit knowledge. Their authors may have known what they were doing, but no one else does. This leads to so-called tribal knowledge.
Not only is implicit encoding harmful for collaboration, but it also hinders the accumulating leverage inherent to technology. Explicit encoding enables others to learn and build upon that knowledge. In the magical training configurations example, we can store training configurations in a database with the author’s notes that link to training results. Teammates can later query for configurations across many experiments to find those that worked best. Learning and new insight is enabled simply by organizing and linking metadata.
Writing the test_for_winged_pedestrian() test function in some python file misses a crucial opportunity for compounding knowledge gains. Winged pedestrians, if properly organized in a taxonomy of concepts under pedestrians, produce leverage across multiple workflow steps beyond testing. That leverage manifests through construction of higher-level queries of the data. Costumed pedestrians is a concept that first must be put in context with other concepts:
Road obstruction
├── Stationary
│ ├── Traffic cone
│ └── ...
└── Non-stationary
├── Pedestrian
│ ├── Average pedestrian
│ ├── Pedestrian with walking aid
│ └── Costumed pedestrians
├── Bicyclist
└── ...
Now imagine a situation where “pedestrians” as a model’s target label may be suffering in performance. Pedestrians with costumes along with pedestrians with canes or walkers, scooter-riders, and other moving obstructions might be valuable concepts to use in a query, perhaps to understand why a pedestrian-detection model may be failing, or to surface unlabeled examples for further labeling. The first step to enabling this is recognizing that test cases, labeling, and error analysis are different facets of the same thing: building domain knowledge.
Testing in the Workflow
In our example, a technician riding along for a road test might notice the error on their laptop screen when it happens. Or a scientist doing error analysis on a model might notice it later. An annotator may find it when new data from a road test is labeled. It may even come up through a failure of a different test in a data preparation pipeline.
Many tools exist to address each workflow step, but often these tools don’t integrate well. The intended experience didn’t account for steps before and after which leads to friction and inhibits overall efficiency. A good platform will blend the seams between the different steps, presenting a unified experience for the developer as they work.
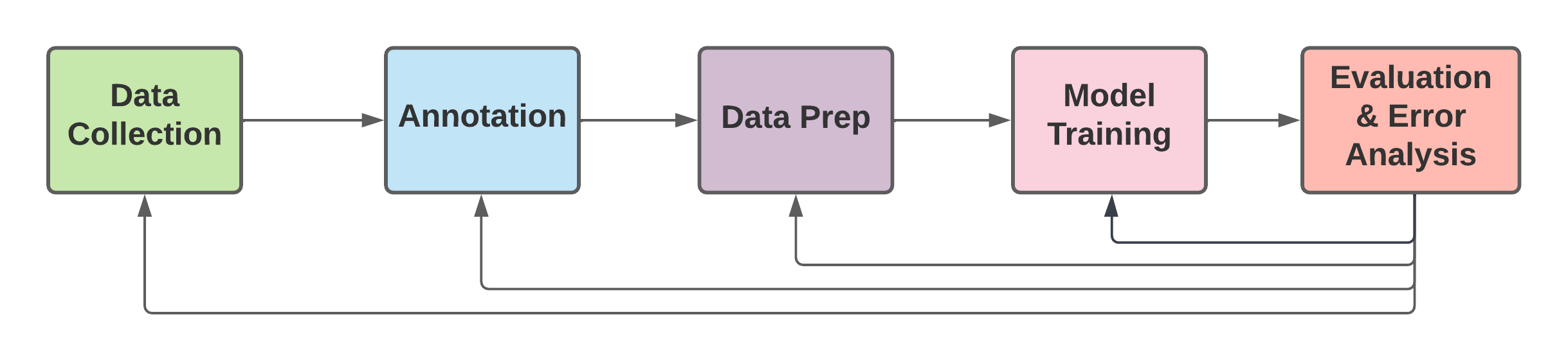
If a problem is found with a data point in annotation, imagine the ability to put a button that says “Add to test suite” directly in your annotation tool.
If the issue surfaces during data collection or data prep pipelines, developers should have anything from pytest to a full-blown tool like Great Expectations for quickly adding a test case.

These interfaces make it easy for a developer to add a test, decreasing the likelihood of model regressions and building the foundations for knowledge sharing.
Case Study: Tesla Autopilot
Andrej Karpathy describes workflows and capabilities atop the internal platform enabling autonomous vehicle development which heavily relies on seeing labeling, testing, and error analysis in the same view.

For a new object detection task, they build a seed set of images and select some as unit tests. As the product and labeling teams iterate they improve on their tests and create new ones. The rest of the process loops until the tests pass.
As Karpathy mentions, the north-star objective for his team is “Operation Vacation”—the idea that the self-driving tasks should improve even if the entire computer vision team were to go on vacation. Implementing that process means the platform is backed by a data model tying metadata around testing, labeling, and model prediction together.
Compounding Gains of Knowledge-Building
When test cases are formulated they are also labeled. If the test scenario significantly affects performance, similar samples can be mined for additional labeling. If the labeling tool makes it simple to add new test cases then we have an efficient process for expanding our knowledge of a test scenario.
These gains compound when considering this process for large swathes of test scenarios. If our model was once sensitive to lighting conditions we may have a concept of “daylight” or “time of day”. We may also imagine, based on intuition, that detecting bicyclists is a helpful step towards detecting costumed pedestrians. We can then construct a query for useful pedestrian detection samples:

Or imagine a visual query component to make parts of the above query easier to construct:
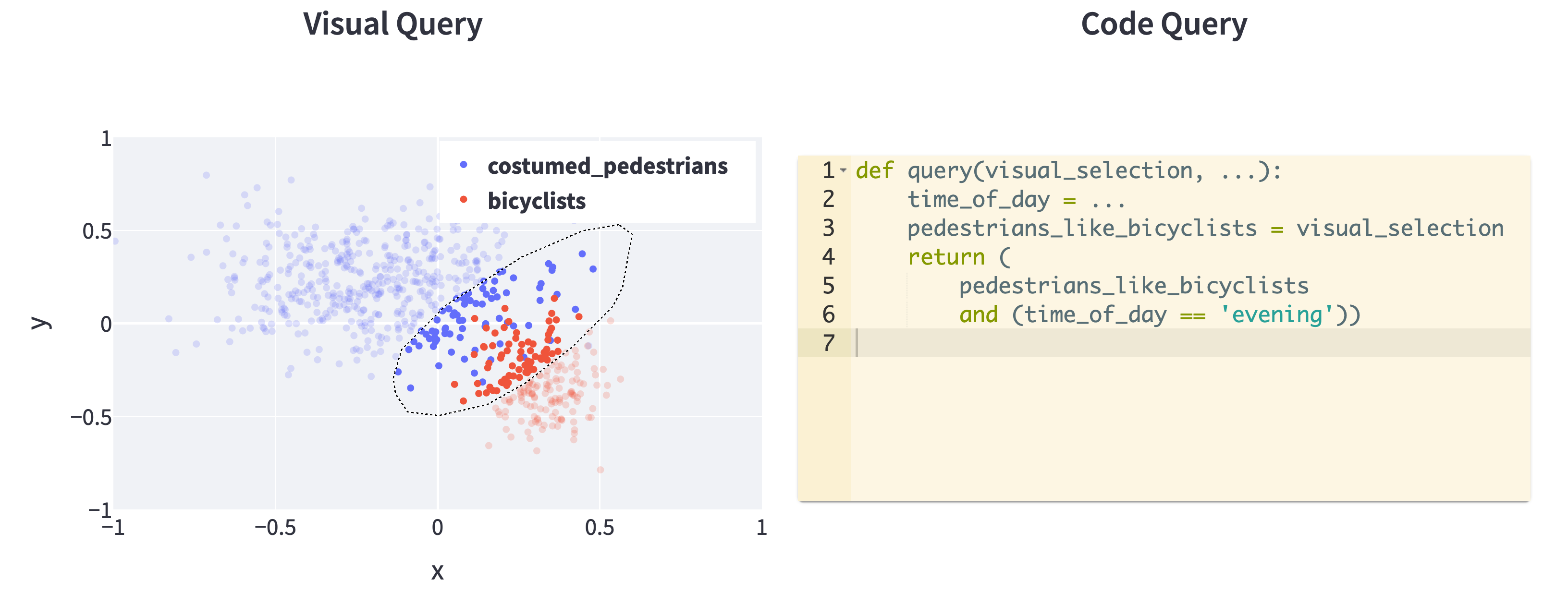
Two things give compounding gains: removing seams for usability, and spending time to explicitly organize knowledge. The Tesla self-driving team demonstrate these gains through a concept of “triggers” to query customer data for labeling.

Developing these queries requires explicitly encoded domain knowledge. Some triggers require understanding concepts in autonomous vehicle development, like the difference between radar and vision or the definition of a bounding box. Other triggers leverage real world concepts, like brake lights, roads, and what constitutes the roof of a vehicle. Many rely on both types of concepts together to implement a trigger. Without definitions for these lower-level concepts, building queries for these higher-level concepts (triggers) would be rather challenging.
Platforms for Knowledge Development
Building knowledge across different development activities requires a platform with a unified data model. Unification is the key to realizing compounding gains from domain knowledge.
But building a platform is challenging for more basic reasons. The breadth of functionality required is immense and feature priorities differ across use-cases, teams, and companies. Open source tools and vendors for MLOps help to a point, but recent sentiments point to a feeling of fragmentation. Platform teams need to wrangle a large number of tools, manage multiple vendors, and build for a long time (sometimes years) until their efforts become fully realized.
Platform teams sometimes prioritize large infrastructure projects in production training and deployment in effort to minimize time-to-market. While this may be a reasonable short-term strategy, it risks building momentum in suboptimal directions.
Platform teams can benefit from thinking about knowledge-building too. The biggest gains in machine learning systems often trace back to a better understanding of the problem. New knowledge is discovered through iteration, so the central goal of a platform should be end-to-end efficiency. Low-hanging fruit in the workflow is observable only when the development engine is running. Platform teams should start that engine by any means necessary, lest they fall into the pitfall of premature optimization. And that may exclude powerful infrastructure to start.
Thinking about frameworks and data models first means infrastructure can be added appropriately for maximum leverage. It does not do to have scalable GPU computing or sub-millisecond serving latency if performance problems are rooted in data or model misunderstanding.
MLOps tools also have a role to play. Tool-builders in the MLOps industry tend to focus on vertical slices of development or deployment use-cases. While this de-risks a product for getting off the ground, users suffer in the long-term by putting pressure on platform teams to integrate. The overhead is vast—each tool has its own language expressed through its UI, APIs, and data formats.
Tools that interoperate easily and strive for a coherent experience provide more value for their customers (both platform teams and the developers they serve) in the long run. Integration is precisely the work platform teams must do over and over again, to the exclusion of bespoke features that contribute to their company’s competitive advantage. If tool-builders care for delivering long term value to their customers, they must prioritize integration efforts over incremental feature development.
Platforms will remain hard to build for the foreseeable future. But companies like Tesla build world-class AI because their platforms enable AI developers to learn about their domain, understand their models, and encode their newfound knowledge into their systems. Regardless of our role in building AI systems, one thing is clear: knowledge-building is core to AI development. Testing may seem unimportant at a glance, but understanding it as a first-class enabler for building knowledge shows it is critical for the successful development of AI.
Find these ideas interesting? Subscribe below and come chat with us on Twitter! @hoddieot @skylar_b_payne
Love this!